2026 全球主流 AI 大模型对比报告(国际+国内)
文档格式:Markdown
更新时间:2026 年 4 月
适用场景:技术选型、采购评估、学习参考
一、国际主流大模型
1. GPT-5.4 / GPT-4o(OpenAI)

- 定位:通用全能型,全球生态最成熟
-
优点
-
综合能力、复杂推理、指令遵循、格式化输出业界顶尖
-
多模态原生一体化(图文/语音/视频),体验流畅
-
API 成熟、插件生态完善,企业落地成本低
-
幻觉率低,适合金融、法律、医疗等高可靠场景
-
-
缺点
-
中文深度理解与本土场景弱于国产头部模型
-
长文本处理成本偏高
-
国内访问受限,数据合规风险较高
-
-
最佳场景:通用办公、产品研发、海外业务、高精度推理
2. Claude Opus 4.6 / Sonnet 4.5(Anthropic)
- 定位:超长上下文 + 高安全合规
-
优点
-
支持 1M+ tokens 上下文,无损处理长文档、代码库
-
输出稳定、幻觉极低,隐私与合规友好
-
代码重构、架构设计、长文本总结能力突出
-
Sonnet 版本性价比极高,适合批量调用
-
-
缺点
-
多模态能力弱于 GPT/Gemini
-
响应速度偏慢,Opus 价格昂贵
-
国内访问不便,生态工具链较少
-
-
最佳场景:法律合同、论文精读、大型代码库、企业合规
3. Gemini 3.1 Pro / Ultra(Google)

- 定位:原生多模态 + 视频/3D 理解 + 科学计算
-
优点
-
视频理解、实时搜索、科学推理能力顶尖
-
超长上下文、低延迟、API 价格极低
-
与 Google 生态深度整合
-
-
缺点
-
纯文本对话、创意写作偏生硬
-
中文适配一般,脱离谷歌生态体验下滑
-
-
最佳场景:视频分析、科研计算、多模态内容生产
4. Llama 4(Meta)
- 定位:开源标杆,私有化部署首选
-
优点
-
开源可商用,支持私有化部署,数据安全性强
-
社区生态丰富,微调方案成熟
-
性能接近闭源头部,成本远低于闭源
-
-
缺点
-
工程化、对齐、安全能力需自研,门槛高
-
产品化体验、多模态弱于商业模型
-
-
最佳场景:企业私有化、研究机构、二次开发、垂直行业底座
二、国内主流大模型
1. 豆包 5.0 / Seed 系列(字节跳动)
- 定位:C 端国民体验,多模态均衡易用
-
优点
-
中文口语化、交互流畅、响应速度快
-
多模态均衡,语音对话自然度高
-
免费额度充足,API 成本低,商业化友好
-
国内合规、访问稳定
-
-
缺点
- 硬核科研、数学推理略逊海外顶流
-
最佳场景:日常助手、文案创作、生活服务、企业轻应用
2. 通义千问 Qwen 3.5 / Max(阿里云)
- 定位:国产开源领军,中文理解顶尖
-
优点
-
中文语义、长文本、多模态能力均衡
-
开源可商用,阿里云生态一体化
-
性价比高,80%+ 指标对标海外头部
-
-
缺点
- 国际化工具链、海外整合能力较弱
-
最佳场景:中文内容、电商、办公、开源二次开发、政务
3. 文心一言 ERNIE 5.0(百度)
- 定位:知识增强 + 强合规,行业落地成熟
-
优点
-
知识图谱+搜索融合,事实准确性高
-
政务、金融、法律合规体系最完善
-
行业套件、RAG、多模态能力成熟
-
-
缺点
- 创意写作、口语交互偏刻板
-
最佳场景:政务、金融、医疗、教育、企业知识库
4. Kimi 2.5(月之暗面 Moonshot)

- 定位:长文本精读天花板
-
优点
-
百万 tokens 上下文无损处理,读书/会议/代码极强
-
数学推理、总结提炼顶尖
-
C 端界面简洁、体验优秀
-
-
缺点
- 企业生态、多模态、私有化能力较弱
-
最佳场景:文献阅读、合同审查、资料整理、研究学习
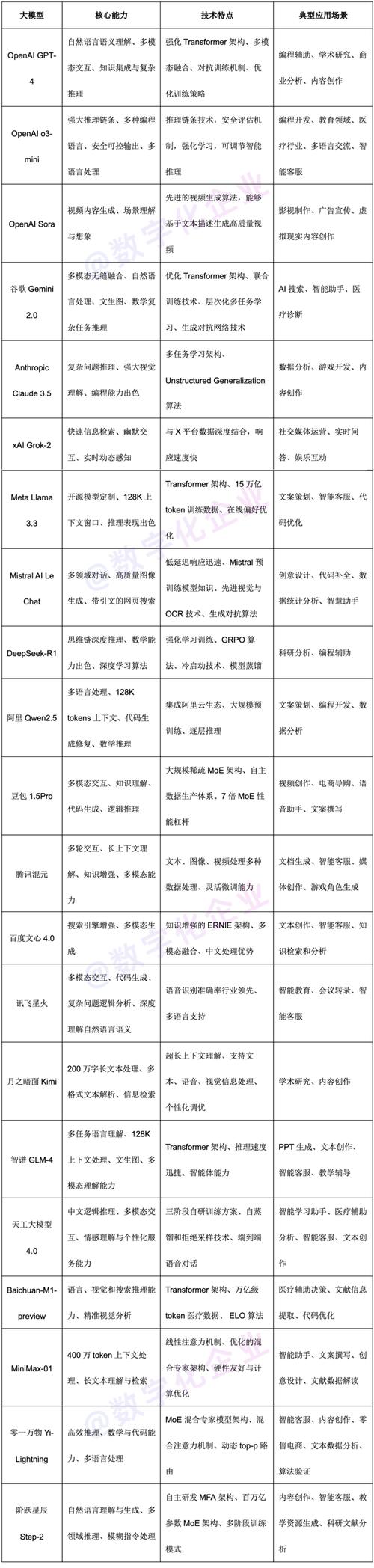
5. GLM-5(智谱 AI)
- 定位:清华技术底座,Agent 智能体 + 国产化适配
-
优点
-
逻辑推理、编程、Agent 能力突出
-
支持国产芯片部署,国产化适配领先
-
开源生态成熟,企业服务稳定
-
-
缺点
- C 端知名度、流量生态弱于互联网大厂
-
最佳场景:复杂 Agent、企业级应用、国产化替代
6. DeepSeek V4 / R1(深度求索)
- 定位:代码/数学推理强者,高性价比开源
-
优点
-
代码、数理推理国内顶尖
-
开源可私有化,API 价格极低
-
-
缺点
- 通用创作、多模态体验偏工程化
-
最佳场景:编程开发、科研计算、私有化代码助手
三、核心维度对比表
|模型|国家|核心优势|短板|最佳使用场景|
|---|---|---|---|---|
|GPT-5.4|美国|全能均衡、生态最强、多模态|中文一般、国内受限|通用研发、海外业务|
|Claude 4.6|美国|超长上下文、代码、低幻觉|多模态弱、速度一般|法律/代码/长文档|
|Gemini 3.1|美国|视频/3D、科学计算、低价|中文弱、文本一般|多模态/科研|
|豆包 5.0|中国|体验流畅、响应快、合规稳定|硬核推理略弱|日常/C端/生活服务|
|通义千问 3.5|中国|中文强、开源、性价比高|国际生态弱|内容/电商/开源|
|文心 5.0|中国|知识/合规/行业套件|创意偏弱|政务/金融/医疗|
|Kimi 2.5|中国|超长文本精读|企业生态弱|阅读/资料整理|
|GLM-5|中国|Agent、国产化部署|C端较弱|企业/复杂任务|
|DeepSeek|中国|代码/数学、低价开源|通用创作一般|编程/私有化|
四、选型建议(直接可用)
1. 海外业务/全球产品 → GPT-5.4
-
长文档/代码/高合规 → Claude Opus / Sonnet
-
多模态/视频/搜索 → Gemini 3.1
-
国内 C 端/日常体验 → 豆包 5.0
-
中文内容/开源商用 → 通义千问 Qwen 3.5
-
政务金融/强合规 → 文心一言 5.0
-
论文/合同精读 → Kimi 2.5
-
代码/私有化/低成本 → DeepSeek V4
-
国产化芯片/智能体 → GLM-5
需要我帮你把这份文档导出为可直接下载的 .md 文件,或按汇报PPT大纲重新排版吗?