豆包、DeepSeek、通义千问、文心一言,谁更适合帮你干活

故事是这样的。
这段时间,我发现一个很有意思的现象。
很多人已经不太把 AI 当「聊天机器人」了。
而是开始把它当一个,能接活的东西。
写个方案。
读个文档。
总结会议纪要。
帮你改稿。
给你列调研框架。
甚至已经开始有人默认,自己电脑里至少要有两三个 AI,像工具箱一样摆着,用的时候顺手切一下。
然后问题就来了。
如果你现在主要用中文,平时干的又是那种很典型的知识工作,写字、查资料、做汇总、做判断、做方案、跑一点轻工作流,那豆包、DeepSeek、通义千问、文心一言,这四个,到底谁更适合当你的 AI 搭子?
说真的,这问题现在还挺现实的。
因为它已经不是一个单纯比模型分数的事了。
你真正用起来,会发现大家比的根本不只是「聪不聪明」。
而是四件事。
第一,它到底能不能听懂你在说什么。
第二,它能不能真的帮你把活往前推一步。
第三,它在中文语境里,到底顺不顺手。
第四,它的短板,会不会刚好卡在你最常用的场景上。
我专门去翻了一圈这几家的公开页面和最近更新,尽量按 2026 年 6 月 2 日这个时间点来看这个问题。
先说结论。
如果你要一个最短答案,我会这么说。
豆包,最像一个顺手、接地气、中文感很强的日常全能搭子。
DeepSeek,最像一个脑力特别猛、推理和代码都很能打的理工型选手。
通义千问,最像一个体系完整、工具链和企业能力都比较重的多面手。
文心一言,最像一个在中文知识、搜索联动和百度生态里更有天然主场感的老牌选手。
但这句话,说完等于没说完。
因为真正有意思的地方,不在于谁最强。
而在于,谁的长板,刚好对上你的工作方式。
先把问题说透。
今天我们聊这四个,不是把它们当成纯模型参数在比。
而是把它们当成四个问答型 AI 智能体来看。

也就是,你打开一个输入框,不只是要它回答你一句话,而是希望它帮你处理任务。
比如:
你给它一堆资料,让它提炼重点。
你丢给它一个模糊问题,让它帮你拆框架。
你让它写稿、改稿、润色、补观点。
你让它读长文档、做总结、列行动项。
你甚至希望它有点「工具感」,最好还能往搜索、知识库、文档、代码、工作流那边再多迈一步。
一旦你用这个标准看,就会发现这四个东西,气质其实差挺多的。
先聊豆包。
豆包给我的感觉,一直都挺像一个很懂中文互联网语境的日常搭子。
它有个很强的优点,就是顺手。
这点别小看。
很多 AI 看着能力很强,但你一真拿来天天用,那个别扭劲儿会非常明显。要么说话太端着,要么太像标准答案生成器,要么明明懂你的字,却不懂你的语气。
豆包这块,整体上是顺的。
我去看了它官网和功能说明,官方自己强调得最多的,还是文字创作、知识问答、生活和工作场景里的高频使用,以及语音、记忆、搜索这些偏产品层的体验。它的备案说明里也明确提到,核心是对话生成,并且会结合预先学习和全网搜索内容来给结果。
这句话翻译成人话就是。
豆包不是单纯想做一个只会陪你聊天的模型。
它想做的是,一个你真的会天天点开的中文 AI 助手。
所以它的强项,通常集中在这几个地方。
第一,中文语感和日常沟通感比较好。
你拿它写短文案、改邮件、润色表达、梳理思路,往往会觉得它没那么拧巴。那种「人说人话」的感觉,会比很多过度学院派的模型更自然一点。
第二,泛知识问答和轻办公场景很顺。
比如总结文章、拆会议纪要、提炼要点、生成初版方案、做轻量调研框架,这些都挺像豆包的舒适区。
第三,产品层能力比较完整。
这里说的不是底层模型论文,而是一个普通人真正会用到的那层东西,语音、记忆、搜索、不同终端、一些偏助手型体验。
也就是说,如果你要的是一个比较生活化、工作化、持续陪跑的 AI,豆包是有那种「我随手就想打开你」的潜质的。
但豆包也有短板。
最大的一个问题是,它虽然很好用,但很多时候你会明显感觉到,它更像一个产品做得很顺的通用助理,而不是一个会让你拍大腿说「卧槽这推理也太顶了」的重脑力选手。
尤其在特别复杂的推理、特别高压的逻辑拆解、或者那种需要一步步非常严密地把问题啃下来的任务里,它未必是你第一个想切过去的模型。
还有一点,豆包的能力呈现,很多时候更偏产品整合,而不是像 DeepSeek 那样把「模型本身很强」这件事挂在脸上。
这不是缺点。
但会影响预期。
你如果要的是每天高频实用、中文顺口、轻任务完成率高,豆包就挺香。
你如果要的是那种带着一点科研气质、解题型、代码型、重推理型的压迫感,豆包就不一定最对味。
再聊 DeepSeek。
DeepSeek 这玩意,这一年多是真的把自己活成了一种气质。
就是那种,脑子很好。
而且不是一般的好。
我查了一圈官方信息,截止 2026 年 6 月,DeepSeek 官网已经把 V4 Preview 放出来了,首页直接写了 stronger Agent capabilities。API 文档那边,2026 年 4 月 24 日又明确更新到了 DeepSeek-V4-Pro 和 V4-Flash。它的 Thinking Mode、函数调用、JSON 输出、OpenAI 兼容接口这些,也已经很成熟了。
这意味着什么呢。
意味着 DeepSeek 现在已经不只是一个大家印象里的「数学和代码很猛」的模型了。
它在往一个更完整的、适合接进智能体和工具链的底座走。
DeepSeek 最大的优点,首先当然还是推理。
如果你的工作里经常有这种场景:
一堆条件摆在面前,要你做判断。
一堆材料扔过来,要你找逻辑漏洞。
一段需求很混乱,要你拆成明确步骤。
或者你要它帮你想程序结构、写代码、补脚本、做技术分析。
那 DeepSeek 的存在感会非常强。
第二个优点,是开放度和工程友好度。
这个东西其实挺关键的。
很多时候,我们选一个模型,不只是看聊天页面好不好用,而是看它能不能被接入更大的工作流。
DeepSeek 在这块的优势很明显,API 兼容、思考模式、函数调用、结构化输出,再加上开源系的形象,本身就很适合拿来做更深入的自动化和 Agent 工作。
第三个优点,是它的「理工脑」真的会让很多复杂任务舒服很多。
有些模型你问一个复杂问题,它会很会说。
DeepSeek 则更像,它会真去算。
会真去拆。
会真去把那个坑挖开。
这对做研究、写代码、搞分析、做高信息密度工作的朋友来说,太重要了。
但 DeepSeek 的短板也很鲜明。
第一个短板,就是它有时候不够讨喜。
这话听着有点怪,但真是现实。
一个模型再强,如果你天天跟它打交道,却总觉得说话没那么顺、产品没那么润、结果没那么「生活化」,你会下意识减少打开它的频率。
DeepSeek 在很多高压脑力场景里很猛,但在一些更偏日常表达、轻社交语境、生活助理式场景下,它未必有豆包那种天然亲和。
第二个短板,是普通用户会有一点门槛感。
不是说它难用。
而是它会天然给人一种,这玩意更适合懂一点的人。
第三个短板,是产品生态的体感广度,至少在普通用户感知层,不一定有豆包和通义那么完整。
你如果只是单纯想找一个,每天写写东西、顺手问问问题、帮你收拾一点工作杂活的 AI,DeepSeek 有时会显得有点大材小用。
它像一把很锋利的刀。
但不是每顿饭都需要上解剖刀。
再说通义千问。
通义千问这家伙,给我的感觉特别像一个大厂体系化选手。
就是那种。
你只把它当聊天机器人看,会低估它。
你一旦把它放到「企业」「工具」「多模型矩阵」「Agent 搭建」这个语境里看,会发现它整个盘子其实很大。
我去看阿里云和通义实验室的官方页面,截止现在,前台已经不只是一个千问聊天框了,而是一整套 Qwen 系列,多模态、代码、视觉、全模态、图像生成,再加上智能体搭建、MCP、长文档解析、信息提取这些能力都摆在台面上。
这说明通义千问最强的地方,可能不是「某一个点特别炸」。
而是完整。
第一,它的能力面很宽。
文本理解、生成、视觉理解、音频、多模态、工具使用、Agent 互动,官方自己都在强调这些能力。
这意味着你如果要做的事,不是一个纯聊天任务,而是一个稍微有点系统性的任务,比如读招投标文件、处理长文档、做知识提取、接企业流程、做业务分析,那通义千问是很容易进入候选名单的。
第二,它和企业侧、平台侧、工作流侧的结合很自然。
很多模型适合个人用。
通义千问则有一种「你往大了搭也行」的感觉。
第三,它在长文档、信息处理、知识提取这种偏干活的场景里,很有实用主义气质。
不是那种特别会表演的 AI。
更像一个愿意埋头干活的中后台选手。
但通义千问的缺点,也很典型。
第一个,是产品线复杂。
对于普通用户来说,这个复杂度有时候会变成一种轻微负担。你会看到一堆 Qwen、VL、Coder、Max、Plus、Flash,然后开始恍惚。
第二个,是它的「人格感」没有那么强。
有些 AI 你用两天,就觉得你认识它了。
通义千问很多时候更像一个很专业的系统,而不是一个很鲜活的搭子。
第三个,是它虽然整体能力强,但对普通用户来说,最强价值有时未必在聊天框本身,而在它背后的整套能力。
这就会导致一种情况。
你如果只是拿它做最基础的问答聊天,可能感受不到它真正厉害的地方。
最后聊文心一言。
文心一言挺有意思的地方在于,它经常被外界讨论热度低估,但它的底子和路线,其实一直没停。
尤其是这半年。
我去翻了百度官方的 ERNIE Blog,2026 年 5 月 9 日,文心 5.1 正式发布,官方自己强调的就是 Agent、推理、创作多维升级。再往前看,文心 5.0 也已经明确在往原生全模态和统一理解能力上推。
这说明文心一言现在不能再用两年前那个印象看了。
它已经不是一个单纯的「百度版 ChatGPT」。
它更像一个站在百度搜索、知识、中文理解和文心体系上的综合选手。
文心一言的第一个优点,是中文知识场的天然主场感。
这个优势很微妙,但很真实。
你做中文问答,尤其是那种带一点常识、资讯、中文表达习惯、中文内容创作、中文信息组织的问题时,文心一言很多时候会有种主场作战的感觉。
第二个优点,是它和搜索、知识增强这条路天然贴得更近。
百度过去这些年的底盘,不管你喜不喜欢,它在信息组织这件事上,确实是有积累的。
所以文心一言特别适合那种,你不是单纯让它发挥想象力,而是希望它把中文知识和生成能力混在一起,为你服务的场景。
第三个优点,是它在企业和平台侧并不弱。
尤其如果你本来就在百度云、千帆、文心这套生态附近活动,那文心一言很多能力接起来会比你想象中顺。
但文心一言的短板,同样明显。
第一个,是很多用户对它的心智,还停留在旧版本时代。
这其实很吃亏。
因为一个 AI 产品,一旦在公众印象里留下过「没那么惊艳」的第一印象,后面哪怕补了很多能力,也要花很久才能把这个心智搬回来。
第二个,是它在极客圈和开发者圈的话题存在感,至少这段时间,没有 DeepSeek 那么强。
第三个,是它的优势很多时候更偏「中文知识和生态整合」,不是那种一上来就让人感到锋利的重推理人格。
所以如果你是一个特别迷恋模型智力压迫感的人,你可能不会第一时间想到它。
但如果你的工作本质上是中文内容、中文信息、中文搜索增强、中文场景里的实际生产,它其实未必像大家以为的那么弱。
聊到这儿,其实可以把四个模型拉到一张桌子上了。
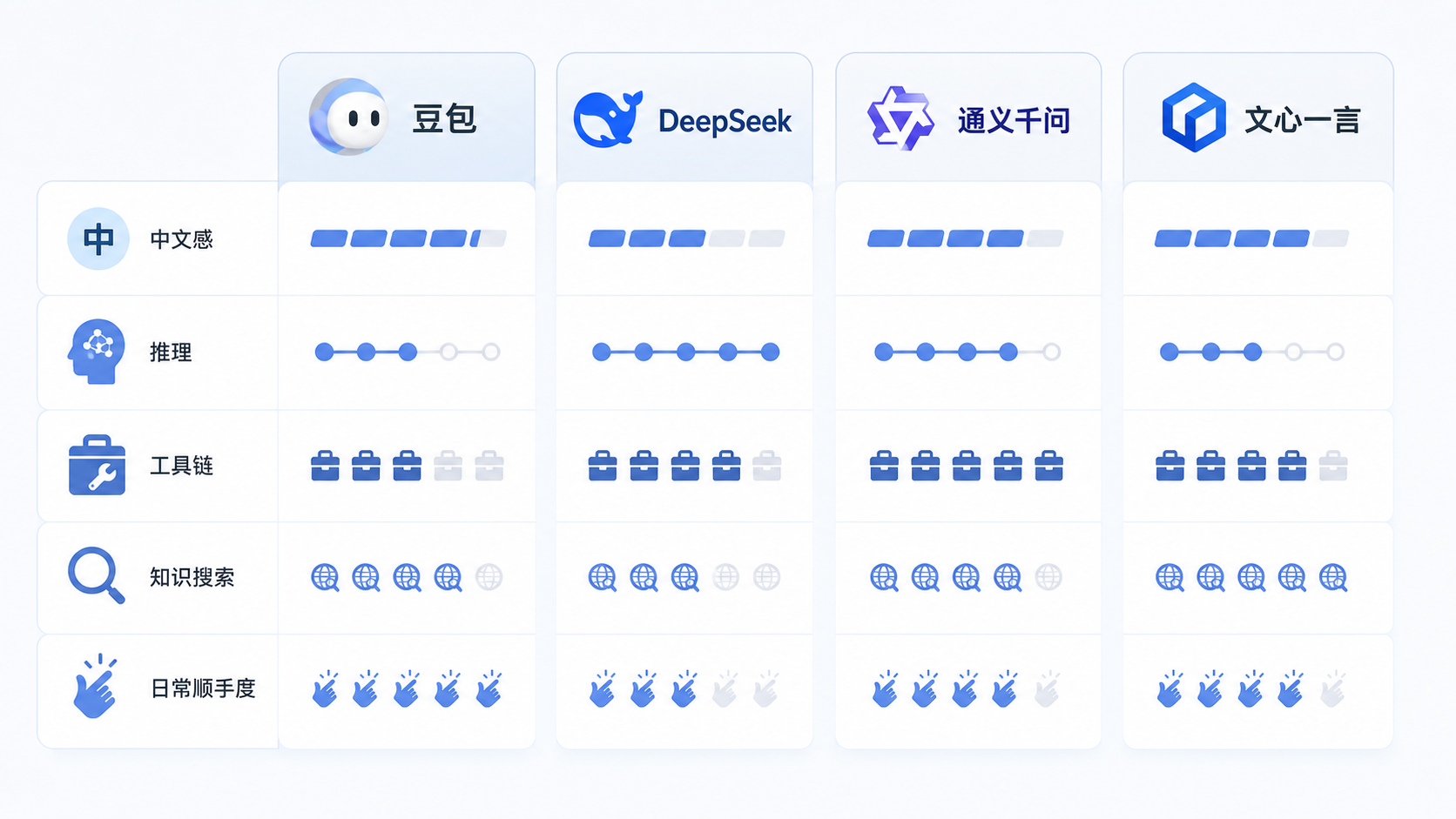
如果把它们都当成能干活的问答型智能体,我会这么看。
豆包,最适合做高频日用型搭子。
你每天都要写点东西、问点东西、改点东西、顺手处理点信息,它会让你觉得很顺,很像一个会说人话的中文助手。
DeepSeek,最适合做重脑力和高难任务的主力。
复杂推理、代码、严密分析、结构化拆解,尤其是你自己也有一点方法意识的时候,它会非常好用。
通义千问,最适合做系统型、平台型、多场景型选手。
它不是只有聊天,它更像一个可以往更复杂工具链上延展的中枢。
文心一言,最适合做中文知识增强和搜索联动更强的选手。
特别是在中文问题、中文内容、中文理解这块,它的主场优势不能忽略。
如果你非要问我,四个的核心优缺点到底是什么。
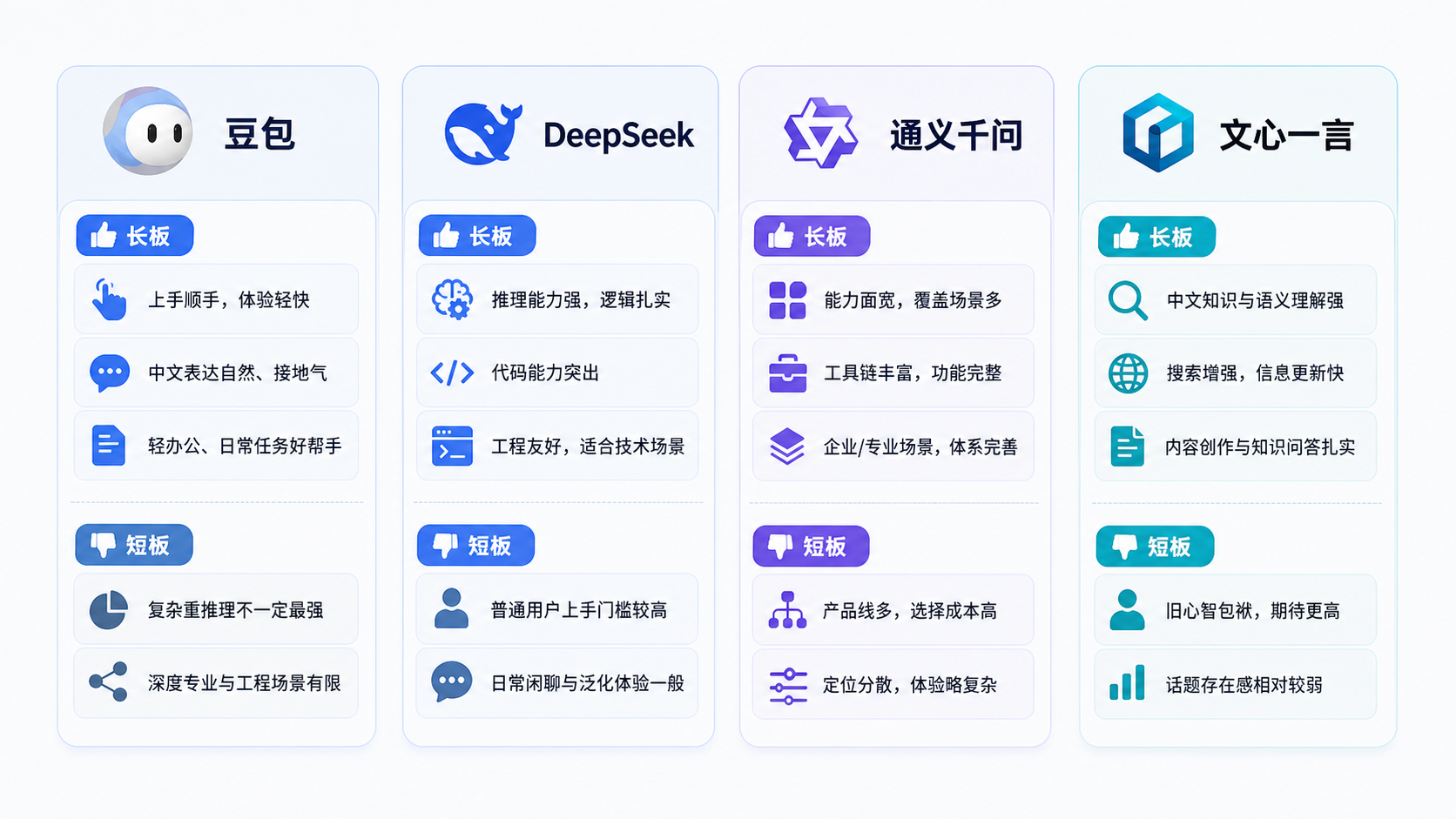
我会压成这几句话。
豆包的优点,是顺手、中文感强、轻办公和日常使用舒服。
豆包的缺点,是在最硬核的推理和复杂任务里,未必最锋利。
DeepSeek 的优点,是推理强、代码强、工程友好、Agent 化潜力大。
DeepSeek 的缺点,是对普通用户来说,可能没那么柔和、没那么轻巧。
通义千问的优点,是能力面宽、体系完整、企业和工具链结合自然。
通义千问的缺点,是产品线复杂,普通用户未必一下能摸到它最有价值的地方。
文心一言的优点,是中文知识场优势、搜索与知识增强路线、生态整合能力。
文心一言的缺点,是旧心智包袱还在,极客圈话题热度也没那么强。
那最后,普通人到底怎么选?

说实话,我不太信那种「只能选一个」的思路。
这都 2026 年了。
很多时候,更现实的答案就是搭配着用。
比如日常问答、轻写作、生活工作碎活,用豆包。
碰到复杂分析、推理、代码、严谨任务,切 DeepSeek。
需要长文档、企业流、工具调用、Agent 方案的时候,看通义千问。
需要强中文知识感、搜索联动、百度生态协同的时候,试文心一言。
你会发现,真正聪明的用法,不是赌谁天下第一。
而是承认每个模型都有自己的脾气,然后把它放到最适合它的位置上。
这其实特别像用人。
有的人反应快,适合先冲上去开路。
有的人脑子深,适合啃硬骨头。
有的人体系感强,适合搭系统。
有的人特别懂本地情况,适合做主场作战。
模型也一样。
你非要让豆包去扮演 DeepSeek,让文心一言去扮演通义千问,让通义千问去扮演一个超级轻盈的日常聊天搭子,最后大概率都会拧巴。
回到最开始的问题。
豆包、DeepSeek、通义千问、文心一言,谁更适合帮你干活?
我的答案是。
没有一个统一答案。
但有一个很明确的判断标准。
别问谁最强。
问谁最适合你手上的那类活。
一旦你开始用这个角度看模型,很多争论,突然就没那么重要了。
因为真正拉开差距的,从来不是排行榜截图。
而是你到底有没有把模型,放到它最擅长的位置上。